没预见这篇著作激勉了一阵狂炒。DeepSeek-R1 推理模子就在特朗普赴任日那天发布,性能基本突出了 GPT-4o,比好意思 OpenAI-o1,成本仅为其十分之一到二十分之一。此次不仅让硅谷懵逼,而且让华尔街也不安起来。 尤其是特朗平常告了任期内投资 5000 亿好意思元 AI 基础身手的星际之门接洽,由软银、OpenAI 和甲骨文操盘,微软、英伟达、ARM 等为技巧伙伴,更是把好意思国的 AI 发展的本钱 + 算力模式推到了一个新的高度,还不必说其他科技巨头每年高达数千亿的本钱开销主要投

没预见这篇著作激勉了一阵狂炒。DeepSeek-R1 推理模子就在特朗普赴任日那天发布,性能基本突出了 GPT-4o,比好意思 OpenAI-o1,成本仅为其十分之一到二十分之一。此次不仅让硅谷懵逼,而且让华尔街也不安起来。
尤其是特朗平常告了任期内投资 5000 亿好意思元 AI 基础身手的星际之门接洽,由软银、OpenAI 和甲骨文操盘,微软、英伟达、ARM 等为技巧伙伴,更是把好意思国的 AI 发展的本钱 + 算力模式推到了一个新的高度,还不必说其他科技巨头每年高达数千亿的本钱开销主要投向 AI。但 DeepSeek 以高效的检会和推理,让砸钱搞 GPU 武备竞赛的 AI 发展模式脱手遭到一些质疑,建立在这一基础之上的 AI 见解公司,不论在一级阛阓,如故在二级阛阓,皆濒临着一次估值的拷问。
比拟之下,DeepSeek 正在探索一条中国式的 AI 发展之路,咱们在对 2025 年 AI 的十个议论中,第一条就提议来,中国将参与基础模子的创新,而不单是是奴婢。辞旧迎新之际,咱们再度对 DeepSeek 进行一次"模式"级别的梳理,分底下四个部分:
1,深度求索有深度
2,萤火和 R1 论文
3,DeepSeek 冲击
4,改写 AI 游戏规章
深度求索有深度
DeepSeek 远远不像是好多先容的、尤其是国外报说念和传闻中的那样,是一家仅成立一年多的 AI 公司。实践上它脱胎于幻方量化基金,这是一家仍是创办了 17 年的、特殊学、计较、研讨和 AI 基因的对冲基金。
2008 年,浙江大学学习信息与通讯工程的梁文锋创立了幻方量化,直到 2014 年,在幻方量化的初创阶段,团队从零脱手探索全自动化交游。
2015 年才是幻方自以为的创始元年,信得过依靠数学与东说念主工智能进行量化投资。"创始团队粗豪陈词、敢于创新、费力奋进,原意成为世界顶级的量化对冲基金。" 2016 年,幻方第一个 AI 模子建立的股票仓位上线实盘交游,算力脱手从 CPU 转向 GPU。至 2017 年底,真实扫数的量化策略皆仍是选择 AI 模子计较。
手脚一家对冲基金,幻方脱手诞生以 AI 为公司的主要发展主张。然则, 复杂的模子计较需求使得单机检会遭逢算力瓶颈,同期日益增多的检会需乞降有限的计较资源产生了矛盾,2018 年,幻方的 AI 团队脱手寻求大限制算力管制有贪图。
其实 2019 年可能是幻方大模子之路的开头,这一年,幻方 AI(幻方东说念主工智能基础研讨有限公司)注册成立,悉力于 AI 的算法与基础欺诈研讨。AI 软硬件研发团队自研幻方"萤火一号" AI 集群,搭载了 500 块显卡,使用 200Gbps 高速集会互联。一年之间,"萤火一号"总投资近 2 亿元,于 2020 年讲求投用,满血搭载 1100 块加速卡,为幻方的 AI 研讨提供算力援救。
幻方 AI 很快又插足 10 亿元建筑萤火二号。2021 年,萤火二号一期诞生以任务级分时调理分享 AI 算力的技巧有贪图,从软硬件两方面共同发力:高性能加速卡、节点间 200Gbps 高速集会互联、自研漫衍式并行文献系统(3FS)、集会拓扑通讯有贪图(hfreduce)、算子库(hfai.nn),高易用性欺诈层等,将萤火二号的性能阐扬额外限。
到了 2022 年,ChatGPT 时刻前夜,幻方仍是成为国内一家最初的 AI 公司,而且手中抓有上万块英伟达 A100 卡和一定数目的 AMD 卡。萤火二号取得了多 800 口交换机互联加中枢膨大子树的软硬件架构革新,冲破了一期的物理为止,算力扩容翻倍。新的 hfai 框架让模子加速 50-100%。集群贯串满载运行,平均占用率达到 96% 以上。全年运行任务 135 万个,共计 5674 万 GPU 时。用于科研援救的闲时算力高达 1533 万 GPU 时,占比 27%。
从中不错推算出,在 2022 年,幻方仍是平均每天用 4.2 万 GPU 时,相配于每天有近 2000 张 GPU 卡在真实满负荷跑科研而不是交游。如果按照其时 A100 每小时云服务的阛阓价,相配于每年在科研方面插足 2 亿元东说念主民币。这么限制的 AI 研讨,在其时的国内处于最初景象,在其时的国际上巨头以外的 AI 初创公司中,也算得上是最初的。
2023 年 4 月 11 日,开源模子 Llama1 和 GPT-4 接踵发布之后,幻方文书作念大模子,2023 年 5 月把技巧部门作念大模子的团队孤苦出来,成立深度求索公司,进攻通用东说念主工智能 AGI。
是以,如果从深度求索公司成立算起,DeepSeek 还不悦 2 年;然则如果从成立幻方 AI 算起,已近 5 年;再从 2016 第一个 AI 股票仓位模子上线交游算起,已近 10 年。
当 2018 年,幻方诞生以 AI 为公司的主要发展主张时,就仍是注定了它将是一家 AI 技巧公司,而对冲基金是其其时主要的欺诈。
咱们不错看到,量化投资与 AI 研讨,组成了幻方基因的双螺旋结构。2019 年,幻方踏进百亿私募,这一年,幻方 AI 成立,况且脱手孤苦构建萤火集群。2021 年,幻方管制基金限制一度突出千亿元,它脱手构建更大更复杂的算力集群萤火二号。幻方的基金管制业务最明后的是 2019 年和 2020 年,当然年收益诀别为 58.69% 和 70.79%,尔后因为行业等方面的原因,量化发展屎流屁滚,但幻方手脚一家 AI 公司突显出来。
如果对比成立于 2010 年的 DeepMind 和成立于 2015 年的 OpenAI,手脚创业公司,幻方与其处于团结期间。DeepMind 和 OpenAI 创偶然皆是刚直的 AI 实验室,以完了通用东说念主工智能(AGI)为服务,而且在这场深度学习革射中起到了前锋作用,从 AlphaGo、AlphaFold 到 ChatGPT,皆是转换性的技巧与居品。比拟之下,幻方 AI 一直在复刻研讨其效果,直到成立深度求索,推出 DeepSeek 大模子。从这少许来说,DeepSeek 取得的配置,是站在巨东说念主的肩膀上。
从 AI 交游模子到幻方 AI,再到 DeepSeek,推动了幻方的对冲基金业务的同期,也一步一步从业务部门孤苦出来,并徐徐重新界说幻方这家公司。幻方 AI 的发展离不开对冲基金业务的援救。进行永久的 AI 研讨,离不开资金与算力资源的强有劲援救。DeepMind 临了被谷歌收购,手脚一家孤苦的公司,它一直亏欠,但手脚一家 AI 研讨实验室,在谷歌里面的作用是计谋性的。
我在 2017 年采访 DeepMind 创始东说念主哈萨比斯时,他告诉我说,谷歌收购 DeepMind,便是为了推动从出动第一到 AI 第一的计谋转型。在 ChatGPT 之后,谷歌更是对其里面显得狼藉的 AI 研发和业务进行了整合,一起归并到 DeepMind 旗下。
相通,OpenAI 也从非谋利改选为谋利。其中微软先后投资达 140 亿好意思元,对于 OpenAI 能络续以大算力鼓动 Scaling Law ( 膨大定律),以大资金和高估值眩惑全球顶尖东说念主才,成为一家生成式东说念主工智能的领军企业,阐扬了至关紧迫的作用。
对于扫数的技巧公司来说,AI 大模子将成为其技巧底座,也将重构扫数企业的 IT 和软件部门,这不错部剖析释为什么一个企业内生的 AI 智力,强大到一定进度,有可能界说出企业新的增长弧线。
从 2019 年幻方脱手构建萤火一号脱手,就注定了它走上了一家 AI 公司的轨迹。2021 年,幻方构建萤火二号,在亚太第一个拿到 A100 卡,在 ChatGPT 之后,幻方成为寰球少数几家领有上万张 A100 GPU 的机构。投资十多亿元构建万卡级算力集群,这不会是只是用于炒股。
而硅谷和 Alex 王和 Dylan Patel 等,在 DeepSeek-3V 推出之后,更是服气 DeepSeek 领有 5 万块 H100。不管怎样说,在 DeepSeek 作念研讨,应该是中国完了 GPU 解放的场地。
DeepSeek 与 DeepMind 和 OpenAI 一样追求东说念主才密度,所不同的是,后两者接纳了全球最优秀的 AI 东说念主才,而前者目下只接纳了国内最优秀的东说念主才。记稳健时我采访哈萨比斯时问过相通的问题,他回复说:DeepMind 眩惑了全球 60 多个国度顶尖的博士生和科学家。
DeepSeek 从一家对冲基金的技巧研讨部门,徐徐将其母体迁移为一家 AI 公司,这是一个非常特殊的例子。对冲基金和 AI 技巧皆来自好意思国,但不论是华尔街的对冲基金、如故从华尔街海归作念量化的团队,莫得一个能像幻方这么,进化出一个作念通用 AI 大模子的中枢智力,举例,彭博也曾很早推出了 BloombergGPT 大模子,然后就莫得然后了。从这少许上来说,DeepSeek 这个原土团队是私有的,莫得"模式"可谈。
然则,DeepSeek 也蹚出了一条路,可能用 500 万好意思元、千张 GPU 卡检会出高性价比的模子,这让好多在巨头眼前感到颓败、纷繁撤废预检会的初创 AI 企业,脱手重新想考它们的计谋,从这少许来说,DeepSeek 首创了一种"模式"。
萤火和 R1 论文
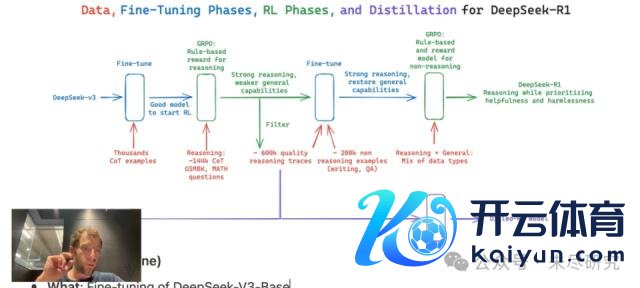
2024 年,DeepSeek 承接发布了从 V1 到 V3 三个基础模子版块,一起开源,如果看其研讨部门之前几年发的论文和技巧博客,不错领会这亦然动须相应的闭幕。咱们在客岁底的著作里先容了 DeepSeek 的 8 篇论文,这里再补充先容两篇。一篇是被国际 AI 界庸碌颂赞为 2025 年迄今为止最好论文的 R1。
它的亮点包括:对基础模子径直上强化学习,而不是先用集会起来非常耗时的监督数据进行检会;选择了群体策略相对优化(GRPO ) ,强化学习检会的成本和复杂性皆得到了显贵缩短,同期保持了较好的性能阐扬;还蒸馏了 6 个 Qwen 和 Llama 的小模子,用起来愈加检朴,而且针对规模的性能愈加强大;特别是 DeepSeek-R1-Distill-Qwen-1.5B 在数学基准测试中优于 GPT-4o 和 Claude-3.5 Sonnet。它不错装到一个手机里。
这里要特别说起论文中有一段,用散文化的说话,描写了在检会进程中出现的模子自我"顿悟"的时刻:
"在 DeepSeek-R1-Zero 的检会进程中,不雅察到一个特别真义的征象,即"顿悟时刻"(aha moment ) 的出现。这一时刻出当今模子的中间版块中。此时,DeepSeek-R1-Zero 学会了重新评估其运行方法,为问题分派更多的想考期间。这种行径悠悠忘返,不仅讲明了模子推贤慧力的提高,也例证了强化学习如何带来无意且复杂闭幕。
这不仅是模子的‘顿悟时刻’,亦然研讨东说念主员的‘顿悟时刻’,他们不雅察到了强化学习的力量与好意思感:咱们并未明确劝诱模子如何管制问题,而是为其提供了正确的激励,使其自主发展出高等的问题管制策略。‘顿悟时刻’有劲地提醒咱们,强化学习有后劲在东说念主工系统中解锁新的智能水平,为将来更自主和自顺应的模子铺设说念路。"

一个真义的"顿悟时刻"出当今 DeepSeek-R1-Zero 的中间版块中。该模子学会了以拟东说念主化的口吻重新想考。这对咱们来说亦然一个顿悟时刻,让咱们见证了强化学习的力量与好意思感。(来源:DeepSeek R1 论文)
如何构建一个高效的万卡算力集群?DeepSeek 发布于 2024 年 8 月的论文,先容了高性价比的萤火 AI-HPC 架构,提议了深度学习的软件与硬件一体化联想的理念。按姓氏拼音字母,创始东说念主梁文锋排在第 17 位作家。
这篇论文总结了构建萤火二号的教授,配备 10,000 个 PCIe A100 GPU,其性能接近英伟达的 DGX-A100,同期将成本缩短了一半,能耗减少了 40%。
DeepSeek 团队特别联想了 HFReduce 以加速 allreduce 通讯,并实施了多项措施以确保计较 - 存储一体化集会无拥塞。通过咱们的软件堆栈(包括 HaiScale、3FS 和 HAI-Platform),还通过访佛计较和通讯完了了显贵的膨大性。
从中不错看出,DeepSeek 的策略,是用接近最先进的大模子和基础身手的性能,联想出远超其接近性的高性价比的居品,参与国际大模子竞争。
DeepSeek 冲击
DeepSeek-R1 仍是成为 MIT 和斯坦福好意思国顶尖高校研讨东说念主员的首选模子。以至有研讨东说念主员暗示,它仍是代替了 ChatGPT。其实最大的受益者,应该是中国用户,它让好意思国在大模子上对中国的卡脖子基本无效了,中国大多数用户以后不错用上和好意思国基本相配的 AI 模子和欺诈。
全球最掀开源平台 HuggingFace 团队,也讲求文书复刻 DeepSeek-R1 扫数 pipeline。完成之后,扫数的检会数据、检会剧本等,亦将一起开源。DeepSeek 已飙升至 HuggingFace 高下载量最多的模子,仅 R1 下载仍是突出 13 万次(本文截稿时为止),蒸馏小模子如 Qwen 32B 和 1.5B,也皆名列三甲。
DeepSeek-R1 激起了开辟东说念主员极大的关爱,应付媒体和社区网站上,寰球兴奋地分享着我方的尝试,并沟通着对他们的 AI 开辟意味着什么。用户评请问,DeepSeek 的搜索功能当今优于 OpenAI 和 Perplexity ,惟一 Google 的 Gemini Deep Research 不错与之匹敌。
尤其是在基础模子上径直强化学习,成为无边 AI 实验室及研讨东说念主员纷繁选择的新范式,为了进程中追求 DeepSeek 的那一"呵哈时刻",港科大助理援助何俊贤团队,只用了 8K 个样本,就在 7B 模子上复刻出了 DeepSeek-R1-Zero 和 DeepSeek-R1 的检会。
一些团队讲明,选择了 R1-Zero 算法——给定一个基础说话模子、提醒和实在奖励信号,运行强化学习,小到 1.5B 的开源模子,欺诈于一些游戏当中,皆能复现出管制有贪图、自我考据、反复校正、直到管制问题为止。1.5B 模子更是不错下载得手机上,在数学等性能上,相配于领有了一个性能相配 GPT-4o 和 Claude 3.5 Sonnet 的最先进闭源模子。
好意思国的主流交易、财经、以至详细时政媒体,也脱手报说念 DeepSeek 征象。CNBC 对 AI 独角兽 Perplexity 创始东说念主 CEO Aravind Srinivas 的专访,从一个技巧产业民众的角度,对 DeepSeek V3 的亮点进行了点评:
需求是创新之母。正因为他们必须寻找变通有贪图,他们最终建造出了一个效力更高的系统。"除非在数学上能讲明这是不行能的,不然你总能想出更灵验率的有贪图。"
性价比。"他们推出了一个成本比 GPT-4 低 10 倍、比 Claude 低 15 倍的模子。运行速率很快,达到每秒 60 个 token。在某些基准测试中阐扬相配或更好,某些则稍差,但总体上与 GPT-4 水平相配。更令东说念主讶异的是,他们仅用了约莫 2048 个 H800 GPU,相配于 1000-1500 个 H100 GPU,合计较成本仅 500 万好意思元傍边。这个模子免费绽开,并发布了技巧论文。"
好意思妙的技巧管制有贪图。"开头,他们检会了一个搀和民众模子 ( Mixture of Experts ) ,这并遏止易。东说念主们难以追逐 OpenAI,特别是在 MOE 架构方面,主若是因为存在多量不规章的损失峰值,数值并不牢固。但他们提议了非常好意思妙的均衡有贪图,而且莫得增多额外的技巧修补。他们还在 8 位浮点检会方面取得冲破,好意思妙地详情了哪些部分需要更高精度,哪些不错用更低精度。据我所知,8 位浮点检会的领会还不够真切,好意思国的大多数检会仍在使用 FP16。"
Perplexity 仍是脱手使用 DeepSeek。他们提供 API,而且因为是开源的,咱们也不错我方部署。使用它不错让咱们以更低的成本完成好多任务。但我在想的是更深层的问题:既然他们能检会出如斯优秀的模子,这对好意思国公司来说,包括咱们在内,就不再有借口说作念不到这少许了。
DeepSeek-R1 开源,仍是逼得 o3 mini 免费!

从硅谷到华尔街,分析东说念主士仍是脱手想考,DeepSeek 可能对热炒 AI 的好意思国本钱阛阓,从一级到二级,会带来多大的影响。中国企业地板价的 AI 服务,会不会冲击好意思科技巨头的估值,AI 关系基础身手的投资限制,等等。科技巨头每年大皆的 AI 本钱开销,短期内是否值得。好意思国 AI 见解股,是否需要来一次重新估值呢?而中国的 AI 见解股,是否也需要来一次重新估值呢?有东说念主开打趣说,DeepSeek 背后的幻方量化,在发布 V3、R1 的同期,幻方不错建立起作念空好意思国 AI 见解股的策略。
DeepSeek 也在调动硅谷的 AI 初创企业估值,让风险本钱多数一口同声站在 DeepSeek 一边,他们找到了杀价初创公司的最好原理:我 pre-A 给你 500 万好意思元,你聪颖出点啥?望望东说念主家的孩子,望望 DeepSeek!
难说念你们皆把钱用来买 OpenAI 的服务了吗?当今不是有 DeepSeek,低廉 10 倍到 20 倍呵!而且,紧接着 DeepSeek,字节的豆包 -1.5-pro 也推出了,比 DeepSeek 低廉 5 倍,比 o1 最多低廉 200 倍!
就连 OpenAI 刚刚推出的智能体 Operator,惟一月费 200 好意思元的订户智力使用,然则,用 DeepSeek 不错作念出相通好的开源免费版块,而且仍是有四五个了。
AMD 响应很横暴,仍是把 DeepSeek-V3 集成到了 Instinct MI300X GPU 上。
用 DeepSeek,还出现了一些新的玩法:如 RAT,( retrieval augment thinking ) ,把 R1 的推理进程,嫁接到任何一个大型说话模子上,不错显贵提高其性能,并获取函数调用和 JSON 模式。
这位小哥在用 DeepSeek 开辟了一个研讨智能体。
不外也有一些研讨东说念主员暗示,DeepSeek 模子在追踪永久间对话的配景等方面,其智力与破耗更高的竞争敌手模子比拟,还有欠缺。
改写 AI 游戏规章
此次杨立昆最有话说。"与其说是中国正在超越好意思国 AI,不如说是开源正在超越闭源 AI。"
开源与闭源
面对好意思国的顽固和巨头的武备竞赛,中国的一些 AI 企业遴荐了一条不同的说念路——开源。较低的成本不错作念出优秀可用的推理模子,而且好的模子迁移为更"杀手"的欺诈,似乎是更灵验的旅途。DeepSeek 莫得在欺诈方面花一分钱扩充,但它仍是在国内和国际的各大欺诈商店占据榜首。这让一些 AI "小龙"们重新想考,回来技巧,拥抱开源,如最近 MiniMax 蹂躏转向开源。

开源大致集聚全球社区的力量,加速大模子的研发和欺诈创新。开源模子更容易被庸碌选择,尤其是在算力和东说念主才资源有限的国度和行业。 通过开源,中国有契机在全球 AI 规模建立我方的技巧方法。开源模子(如 DeepSeek、阿里 Qwen 等)以高性价比著称,有助于推动 AI 技巧的普惠化,将 AI 技巧扩充到全球南边国度,
DeepSeek 会影响无边企业 AI 计谋。跟着成本缩短和绽开打听,企业当今不错遴荐替代时髦的专有模子,举例 OpenAI。DeepSeek 的发布可能会使前沿 AI 功能的打听变得民主化,使较小的企业大致在 AI 武备竞赛中灵验竞争。
Aravind Srinivas 进一步指出了为什么好意思国地精英阶级脱手产生的担忧更具计谋真义:"比起试图遏抑他们(中国 AI 企业)追逐,更危机的是他们当今领有最好的开源模子,而扫数好意思国开辟者皆在使用它进行开辟。这更危机,因为这意味着他们可能会掌抓通盘好意思国 AI 生态系统的心智。历史告诉咱们,一朝开源赶上或超越闭源软件,扫数开辟者皆会转向开源。"
中国与好意思国
在好意思国对中国实施芯片顽固的配景下,DeepSeek 展现了一种信得过的创新——需求推动的创新。中国企业在仅能从中邦原土企业获取比好意思国逾期一两代 GPU 要求下,依然大致开辟出优秀的基础模子。这种创新不单是依赖于 GPU 和本钱的武备竞赛,而是通过算法、架构和工程的创新完了了冲破。
对于 OpenAI 的护城河问题,2023 年 5 月,在 Meta 发布了 Llama 开源模子后不久,谷歌里面即有东说念主提议,咱们莫得护城河,OpenAI 也莫得。
今天,是这一问题再次提议的时候了。开头是 OpenAI 的护城河在那儿。跟着 AI 技巧进入实践欺诈规模,性价比成为关节要素,而非单纯追求最先进的模子。OpenAI 等公司插足数十亿以至上百亿好意思元进行预检会和基础身手建筑,但如果其技巧护城河不够深,其交易模式将濒临挑战。这种高插足的模式是否可络续,成为从硅谷到华尔街令东说念主感到张惶的问题。
DeepSeek 仍是讲明,好意思国无法在 AI 规模获取全皆的竞争上风,以至那些科技巨头皆无法取得全皆的上风。
应该看到,以 AI 发展的全栈技巧来看,中国与好意思国依然有彰着的差距。越往底层走,差距越彰着。在 AI 芯片规模,从 GPU 到 HBM,中国自主技巧的差距在两代到三代。而这一轮 AI 创新的一个凸起特征,是科技巨头主导的,它们领有好处芯片(ASIC)、数据中心、云计较、AI 平台及器具链、操作系统、杀手级欺诈,建立起全栈技巧的垂直整合体系,其中尤以亚马逊、微软、谷歌这三大云服务巨头为代表。
OpenAI 也在向一家 AI 科技巨头演变,它依然领有强大的技巧智力和品牌影响力。它正在从基础模子向高卑鄙膨大,建立起我方的欺诈芯片团队和数据中心,加速布局基于推理模子的智能体,并全面探索其交易模式,如果时髦的而又顶端的推理和智能体技巧,最终讲明能管制复杂和有价值的问题,在性价比上依然领有强大的竞争力。
Srinivas 以为 Meta 仍然会开辟出比 DeepSeek 3 更好的模子,"不管他们叫它 Llama 4 如故 3 点几"。他特别强调了 Meta 在开源规模的孝顺:"实践上,Meta 的 Llama 3.3 技巧酬金非常细心,对科学发展很有价值。他们分享的细节仍是比其他公司多得多了。"比拟之下,DeepSeek 的技巧酬金莫得公布检会数据来源。
Srinivas 以为,与其牵挂中国的追逐,更紧迫的是保持创新势头,连接推动技巧跳跃。"咱们不应该把扫数元气心灵皆围聚在遏止和遏抑他们(中国 AI 企业)上,而是要戮力在竞争中胜出。这才是好意思国东说念主作念事的方法——便是要作念得更好。"
对攻的比赛更精彩。蛇年让咱们期待 Llama 4,Grok 3,也期待 OpenAI-o4, Claude-4, 还有 Gemini-2.5 或者 3欧洲杯体育,以至 GPT-5。
官方网站

关注我们
联系地址